
type
status
date
slug
tags
summary
category
password
icon
昨天谷歌发布Imagen3(文生图模型)最新版与Veo2(文生视频模型)
Imagen3
Imagen3已能在Google Labs中体验使用,刚体验完,感觉相比DALLE3(OpenAI文生图模型),指令遵循能力明显变强,让它画什么就画什么。效果也不错,但真实效果需进一步测试
Google Labs地址:

以下是用Imagen3所生成图片(官方样图):





谷歌还在imagen3基础上做出“Whisk”这个工具,同样发布在Google Labs中,刚体验完,效果非常炸裂,我只能说:mind-blowing
地址:

这是一个融图工具,有三个选项供用户选择(不必全选):主体,场景,风格
三个选项均可通过上传图片或者文字形式自定义
我实测下来暂时感觉非常炸裂,没错,炸裂。来看看官方视频演示:

视频中为图片加上提示“主体在开飞机”,最终效果:

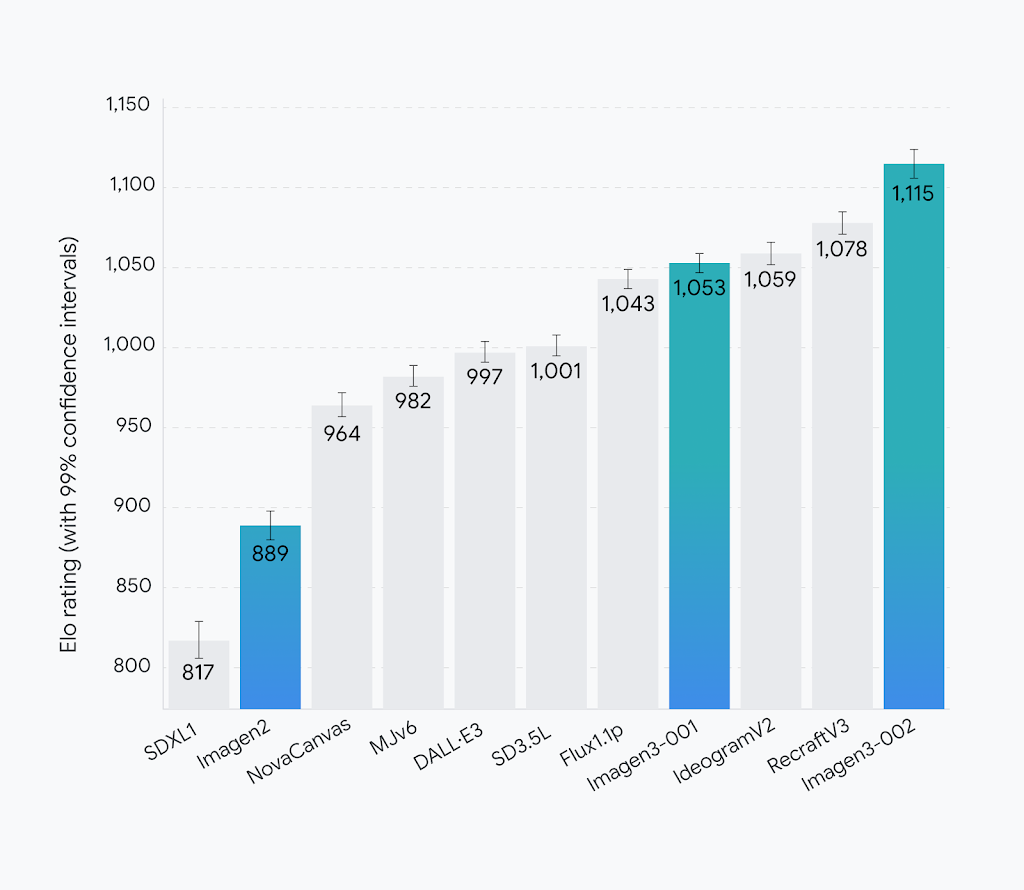
Imagen3与其他文生图模型对比:
Veo2
Veo2为谷歌自家第二代文生视频模型,能生成最高4K分辨率视频,且效果自然,对物理定律理解很好,这个从Veo2生成的流体(水)运动的视频中可以看出
以下是一些Veo2文生视频样片(GIF,原片为4K分辨率,非常清晰):






所以,不提前说,你能一眼看出这些是AI视频吗?
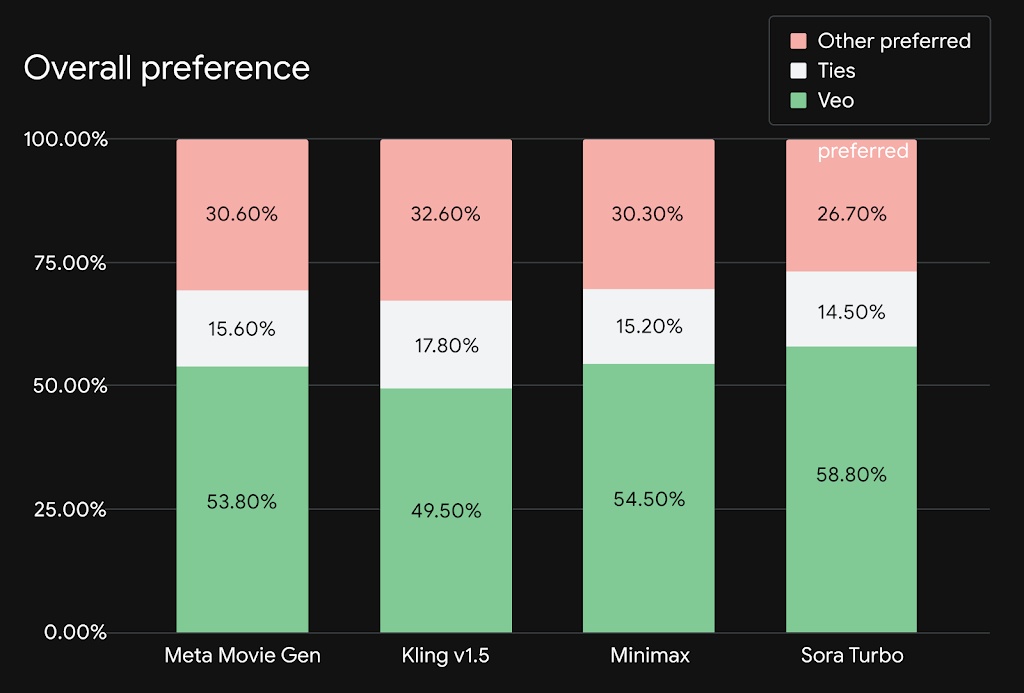
Veo2在测试中超越现有所有文生视频模型:
ChatGPT搜索功能开放、增强,嵌入高级语音功能
ChatGPT昨天宣布SearchGPT向免费用户开放,同时加快搜索功能检索速度以及加入地图展示,最后是高级语音功能现在可以对话时直接让ChatGPT联网回答问题
相比谷歌AI更新,ChatGPT三句就概括完了。。
最后一个嵌入高级语音,刚才测试居然还不能用,应该要过两天才有
- 作者:文雅的疯狂
- 链接:https://www.aiexplorernote.com//article/imagen3-and-veo2
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。







