
type
status
date
slug
tags
summary
category
password
icon
虽然现在大模型能联网,获取最新信息,但这并不能保证大模型联网搜索并参考信息回答我们的问题时给出的信息就不用检查或二次确认。大模型自身的“幻觉”是一方面。比如有时候它以为它知道的某件事是对的,但其实不对或者已经过时了,在搜索时不进行搜索确认导致错误,或者说它在发现自己的错误方面暂时是无能的
还要提防的是互联网上的垃圾信息,实际上互联网上的垃圾信息并不少。大模型联网获取信息后并没有像我们一样辨别信息真实性的能力,它只会搜到就参考。而且现在的大模型并不能有意识地执行二次或多次搜索以确保信息的准确性
主要是对话后台机制的问题。现在所有主流AI每次回复都只会最多进行一次搜索,进行多次搜索确保信息准确性的范式常见于AI Agent。现在的对话式AI中,OpenAI的o1模型和这个思路倒挺像,如果未来给它加入联网能力,有可能实现上面说的效果
OpenAI的o1模型本质上就是在做AutoGPT(一个很早就有了的AI Agent项目),个人觉得这个很难。AutoGPT已经做了一年半,在GitHub上获得接近17万颗星,开源社区这么强大的力量都没做出什么,OpenAI真的能短时间做处什么成效吗?
还有一点想提的是要让大模型的搜索信息的能力能够达到像人类一样看完搜索结果页前一两页的内容再回答信息其实是非常困难的。这里面涉及到可能影响最终参考结果的因素非常多
我之前自己写过给ChatGPT API加上联网能力的脚本,使用的是bing API加爬虫API的方案。由于Bing API搜索到的结果都是网页的标题、关键词、摘要,需要先让ChatGPT根据这些内容来判断网页的内容是关于什么的,然后再让它选择最相关的页面使用爬虫API爬取某几个(我个人搭建,由于要付费,当时只让它爬取一个进行仔细分析)页面的全部信息进行参考
即使是ChatGPT,爬取页面的时候一般也只会抽一到三个页面读取详细信息后进行参考,虽然看起来它参考了十几个页面:
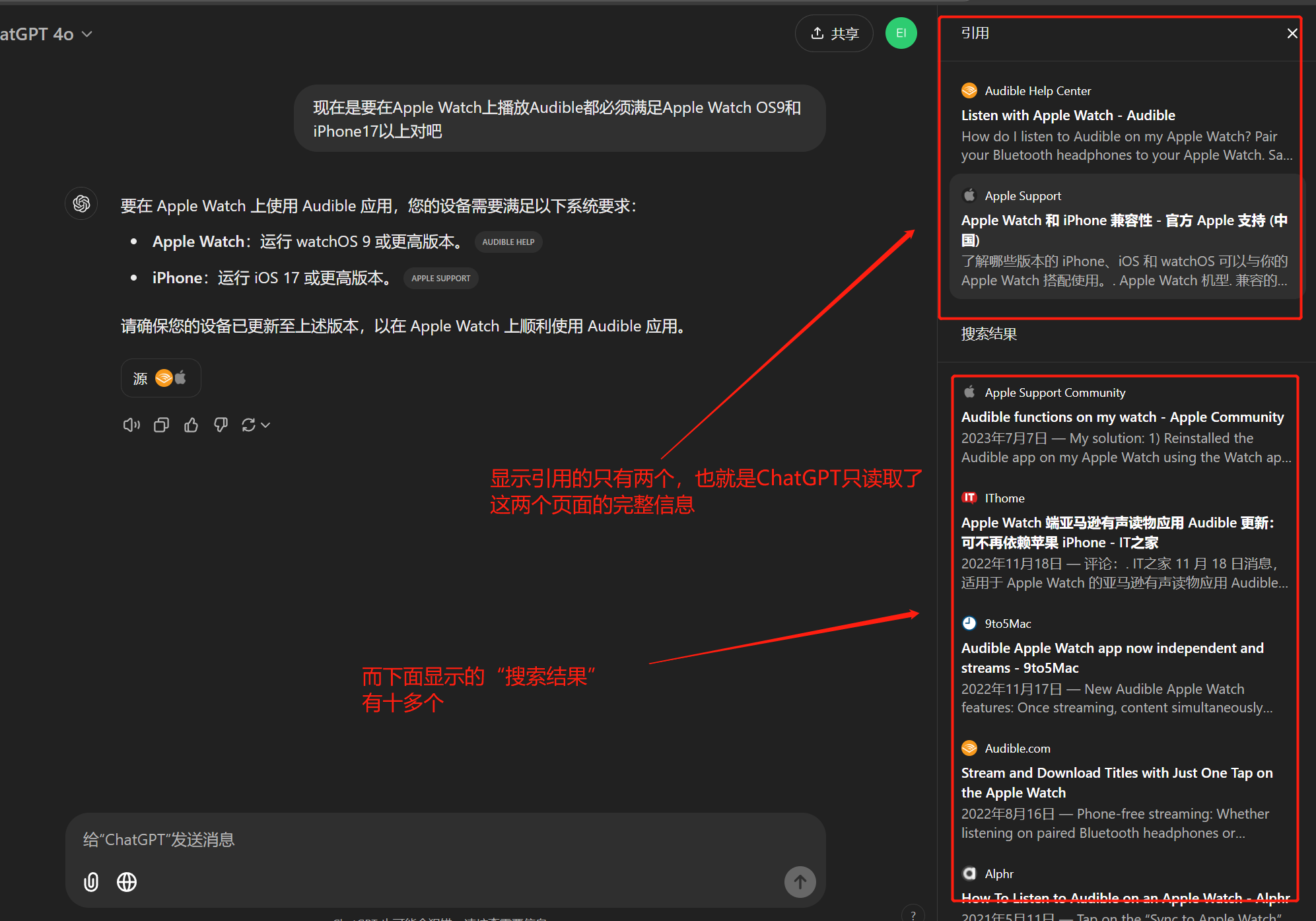
点击ChatGPT回复下面的“源”,可以看到它参考的页面。其中“引用”的部分大概率就是它读了完整页面内容的页面,而“搜索结果”部分里面的页面则很可能是像刚才说的只读取了这些页面的标题、描述等基本信息。这些基本信息在我们自己进行查询活动的时候大多数人实际上只看标题,更别提有些页面的页面描述没写或者和页面内容相关性不大。所以ChatGPT实现查询的过程和人类真实的查询过程其实差别很大
ChatGPT读取页面信息这一点可能有问题的地方也很多,并不存在一个统一的爬虫可以精准爬取所有页面的主体内容。页面的结构多种多样,且爬取到的信息中有很多结构化代码,如果把这些信息加进大模型的上下文中会急速消耗大模型的上下文窗口,成本也会增加,如何处理这些信息是个问题
今天尝试爆破ChatGPT在参考页面时是如何爬取页面内容的,但是没能成功,OpenAI特意针对这个写了一层prompt防御

由于大模型有上下文窗口限制,不可能像人类进行查询活动时看搜索结果页前一两页二十个页面的内容那样把完整的二十个页面内容一次全喂给ChatGPT进行参考,ChatGPT会因为上下文太长能力变差不说,OpenAI真的舍得花这个钱吗?就算舍得也是在ChatGPT Plus订阅涨价的情况下
再往搜索结果页后面看第三,第四页的内容我想都不敢想
除了我这里提到的实际上整个搜索过程还涉及到很多其他因素
现在能理解为什么ChatGPT的最大竞争对手Claude到现在都没有联网能力了,这玩意儿有点类似于智商税
总的来说要人为地给大模型加上所谓的联网能力,通过现在这种即时对话就实现人类自己进行搜索总结答案的过程是不现实的。尽管表面上看起来是这样,实际上用起来不如人意,建议还自己去搜索好,只把ChatGPT搜索当成一个辅助
要真的复现人类进行查询活动完成任务的过程,我觉得可以做一个Agent,给它prompt说一个一个看搜索结果页前几页的内容,最后在这些结果的基础上干嘛干嘛
所以Agent是一个重要的AI发展方向,目标就是创造一个能最大程度上复刻人类活动,代替人类完成任务的机器人
问题的根源在于大模型没有意识,缺少反问的能力,我们不知道它不知道啥,只能通过prompt等技术让它仿照人类普适的活动方式来提高它的性能
以上是我的一些思考
欢迎批评斧正,不喜勿喷
- 作者:文雅的疯狂
- 链接:https://www.aiexplorernote.com//article/is-chatgpt-search-really-useful
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。





.jpg?table=block&id=167d1f9c-c2a3-8042-9a6f-d590795a0ca8&t=167d1f9c-c2a3-8042-9a6f-d590795a0ca8&width=800&cache=v2)

