
type
status
date
slug
tags
summary
category
password
icon
论文链接:[2409.19924] On The Planning Abilities of OpenAI's o1 Models: Feasibility, Optimality, and Generalizability
o1-pewview模型据说在某些测试方面已经达到了人类博士的水平,在大部分测试中超过原先OpenAI最厉害的GPT4o模型
但我一直没怎么用o1-preview模型,因为这个模型还在测试阶段,一个星期才能用四五十次。光是想自己测试o1模型的能力都不够用,索性就不用了,等正式版出来再说
看到这个论文,就想靠它解下这个模型,以下是论文总结和我的一些看法
与先前不同的是,这个模型并不是在“大力出奇迹” 的思路上做的(Scaling-Law,通过不断增加训练的参数量增加模型性能)。原理上主要是利用了Chain-of-Thought (CoT),思维链技术
论文讨论了o1模型在规划任务(planning tasks)方面的能力,主要从三个方面评估:可行性(feasibility)、最优性(optimality)和泛化性(generalizability)
- 可行性(feasibility): 能不能完成任务,生成的计划是否真的可以执行
- 最优性(optimality): 完成任务的方案是否高效,有没有多余的步骤
- 泛化性(generalizability): 换个类似的任务能不能也完成,还是只会做见过的题
研究过程中通过比较o1-preview,GPT4o和o1-mini三个模型在六个任务中的表现测试o1-preview的能力:调酒,搭积木,操控机械臂抓东西,给地板瓷砖涂色,搭建建筑结构,更换轮胎
测试结果是o1-preview和o1-mini模型在所有测试维度中都超过GPT4o模型,如图所示:
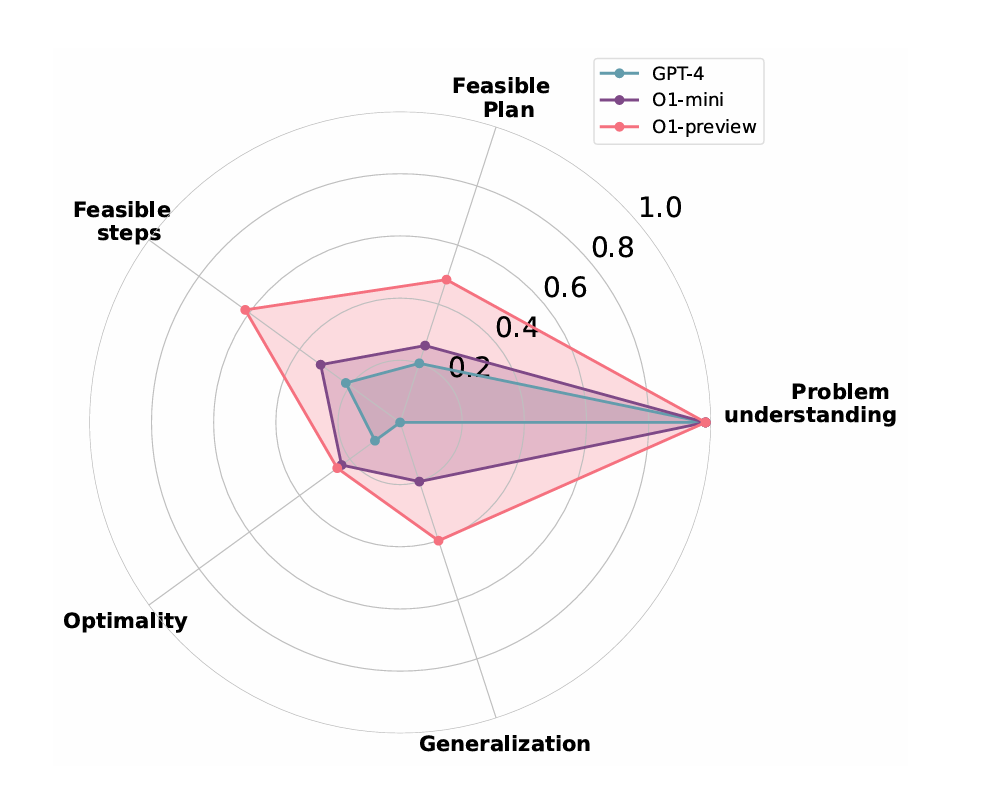
研究结论是o1-preview模型在执行任务时,约束遵循和记忆管理方面优于GPT4o。但是随着任务复杂程度的增加,o1-preview在这两个方面的性能也会慢慢下降(没啥新颖的)
论文提出的改进方向:
- 优化和资源利用:开发更高级的决策机制来减少冗余动作和优化资源使用,比如引入基于成本的推理和从专家示范中学习
- 空间抽象环境的泛化:增强模型在高维和空间动态环境中的泛化能力,改进其处理抽象和复杂规则的表现
- 动态环境处理:提升模型在动态和不可预测环境中的表现,特别是当规则或约束在执行过程中发生变化时
- 约束遵循机制:通过自我评估机制让模型在执行前验证其输出是否符合约束,减少违规错误
- 多模态输入:整合视觉、3D环境等非文本数据,提升模型在空间和物理推理任务中的表现
- 多智能体规划:让模型能处理多个智能体之间的协调,支持基于本地知识的去中心化规划
- 人类反馈:通过人类反馈的交互循环持续改进模型,帮助其适应新情况和任务
个人觉得这些都能通过做一个像AutoGPT那样的Agent实现,所以我一直觉得o1-preview其实就是在做AutoGPT
看完论文又有了一个新想法是,我觉得想要模型更好地实现记忆管理,约束遵循等,要让它具有像人类一样的感官。只有有了视觉,听觉,触觉等感官机器人才能在执行任务的过程中更好的确认任务状态,执行过程中的细节。单纯在语言的抽象世界中执行任务,模型永远脱离不了人类单独完成任务
这已经涉及具身智能了,理论上讲还非常遥远。但是让模型自己去操作电脑,完成一些主要在电脑上完成的任务还是有希望尽快实现的。现在已经有一些像open-interpreter的优秀项目在往这个方向研究,前两天Claude也宣布即将推出类似的功能
而且单纯靠电脑实现的任务还挺多,我的工作基本上就是在电脑上完成的,偶尔用用手机。实现一个能够自己操作电脑完成任务的Agent现阶段还是非常有意义的
- 作者:文雅的疯狂
- 链接:https://www.aiexplorernote.com//article/o1-preview
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。





.jpg?table=block&id=167d1f9c-c2a3-8042-9a6f-d590795a0ca8&t=167d1f9c-c2a3-8042-9a6f-d590795a0ca8&width=800&cache=v2)

